Understanding Machine Learning Embeddings
Machine learning embeddings have become an essential part of various natural language processing (NLP) tasks, such as sentiment analysis, machine translation, and text classification. In this post, we will discuss the concept of embeddings, their applications, and techniques to implement them effectively.
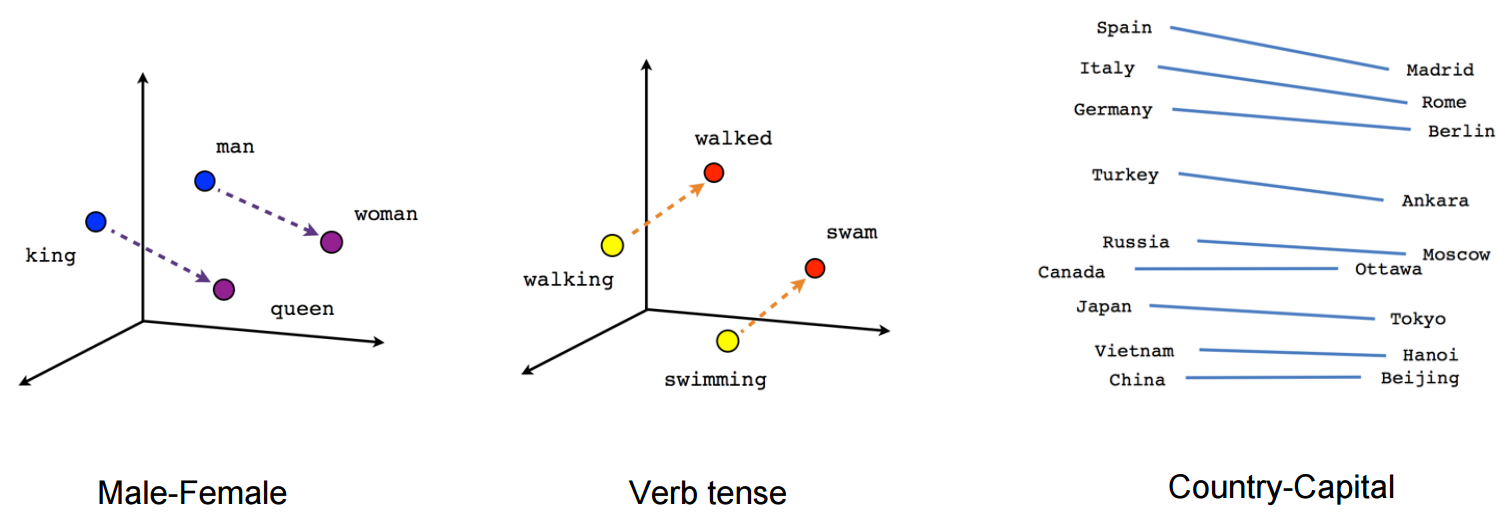
What are Embeddings?
Embeddings are a way of representing complex, high-dimensional data, such as words, sentences, or entire documents, as lower-dimensional vectors. These vectors capture the semantic relationships between the data points, making it easier for machine learning models to understand and process the information.
In the context of NLP, embeddings are used to convert text data into numerical representations that can be fed into neural networks or other machine learning algorithms. The idea behind embeddings is to capture the contextual and semantic information of words or phrases in a compact, continuous vector space.
Applications of Embeddings
Embeddings have found numerous applications in the field of NLP, including:
-
Text Classification: By converting text data into numerical embeddings, it becomes possible to classify documents, such as news articles or product reviews, based on their content.
-
Sentiment Analysis: Embeddings can help in understanding the sentiment or emotion expressed in a piece of text, like determining whether a movie review is positive or negative.
-
Machine Translation: By representing words in different languages as embeddings, it becomes possible to train models that can translate text from one language to another.
-
Recommendation Systems: Embeddings can be used to represent items in a recommendation system, making it easier to find similar items and provide personalized recommendations.
-
Information Retrieval: By representing documents and queries as embeddings, search engines can find relevant documents based on the similarity between the query and the document embeddings.
Techniques for Creating Embeddings
There are several techniques for creating embeddings in NLP tasks:
-
Word2Vec: Developed by Google, Word2Vec is a widely used technique for generating word embeddings. It uses a shallow neural network to learn the vector representations of words based on their co-occurrence with other words in a large corpus.
-
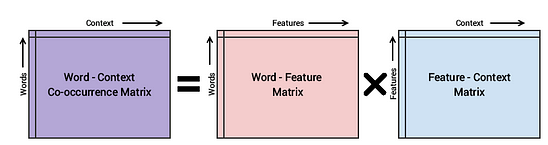
GloVe (Global Vectors for Word Representation): Developed by Stanford University, GloVe is another popular technique for generating word embeddings. It combines the global co-occurrence statistics of words with local context information to create dense vector representations.
-
FastText: Developed by Facebook, FastText is an extension of Word2Vec that takes into account subword information, such as character n-grams, to create word embeddings. This allows FastText to generate embeddings for out-of-vocabulary words and handle morphologically rich languages more effectively.

-
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT is a state-of-the-art technique for generating context-aware embeddings. It uses the Transformer architecture to pre-train deep bidirectional representations of text, which can then be fine-tuned for various NLP tasks.

Conclusion
Machine learning embeddings have revolutionized the way we process and analyze textual data, enabling us to create powerful models for various NLP tasks. By understanding the concept and techniques behind embeddings, you can harness their power in your own projects and build more effective, data-driven solutions.